Pengenalan Suara Berbasis Neural Network dengan Algoritma Momentum Back Propagation
Secara umum, kemungkinan akses ilegal pada suatu ruangan bertambah dengan bertambahnya jumlah pemilik akses. Ini karena media identitas -- seperti bar code, nomor PIN, kartu magnetik, dan kunci -- dapat diduplikasi. Dalam kasus ini, identitas yang melekat pada tubuh menjadi penting. Identitas yang melekat pada tubuh meliputi struktur DNA, retina mata, sidik jari, spektrum suara, dan lain-lain [1]. Dalam penelitian ini Kami menggunakan spektrum suara sebagai identitas untuk akses ruangan.
Alasan pemilihan spektrum suara sebagai identitas ialah berdasarkan fakta bahwa kita masih dapat membedakan suara dua orang berdasarkan suaranya walaupun mereka mengucapkan huruf vokal yang sama. Resonansi vokal dihasilkan oleh artikulator dalam mulut untuk membentuk suara vokal yang berbeda [2]. Karena artikulator hampir unik untuk setiap orang, maka kita bisa membedakan orang dari suaranya. Dalam penelitian ini kami memilih hanya menggunakan vokal "a" dengan alasan penyederhanaan masalah. Kami telah mempelajari bahwa spektrum suara untuk vokal "a" ialah berbeda untuk setiap orang.
Jaringan syaraf tiruan dengan algoritma pembelajaran Momentum Back Propagation digunakan sebagai voice recognizer. Jaringan syaraf tiruan dengan multi-layer perceptron digunakan karena cocok untuk pengenalan pola non-linear [3]. Input bagi neural netwok ialah spektrum vokal "a". Noise dari lingkungan telah direduksi menggunakan metode yang kami sebut self multiplication.
Momentum Back Propagation
Back propagation atau error back-propagation ialah teknik pembelajaran terawasi (superviced learning) yang digunakan untuk melatih jaringan syaraf tiruan. pertama kali dideskripsikan oleh Paul Werbos pada 1974, dan dikembangkan lebih lanjut oleh D.E. Rumelhart, G.E. Hilton, dan R.J. Williams pada 1986 [4]. Algoritma ini berdasar pada aturan delta umum (generalized delta rule):
dengan wij ialah bobot neuron pada layer-i ke layer-j, ialah laju belajar, dan ialah output SSE (jumlah kuadrat error).
Biasanya jaringan syaraf tiruan belajar lebih cepat dengan kenaikan laju belajar, tetapi dapat menghasilkan osilasi bahkan kegagalan belajar. Untuk mereduksi osilasi pada nilai laju belajar yang tinggi, faktor momentum [5] digunakan untuk menjaga kekonstanan kecenderungan proses belajar. Sehingga aturan delta umum untuk perbarahruan bobot menjadi,
dengan ialah faktor momentum.
Teknik Mereduksi Noise
Kami mengembangkan teknik mereduksi noise berdasarkan asumsi bahwa spektrum noise muncul secara acak. Dua sinyal yang mirip (dari sumber yang sama) yang direkam pada saat yang berbeda, tiap sinyal ditransformasi ke domain frekuensi menggunakan Fast Fourier ransform (FFT). Kedua spektrum hasil kemudian dikalikan komponen-per-komponen sehingga komponen spektrum yang muncul pada satu spektrum tapi tidak pada spektrum yang lain -- yaitu noise -- akan direduksi secarad dramatis. Metode ini kami sebut perkalian sendiri (self multiplication). Gambar 3.1 mengilustrasikan metode self multiplication dalam mereduksi spektrum noise.
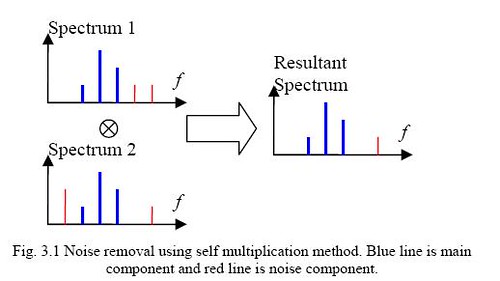
Perhatikan bahwa metode ini menjaga komponen yang muncul pada kedua spektrum. Sehingga jika komponen noise muncul pada kedua spektrum, metode ini tidak bisa mereduksi noise tersebut.
[perhatikan bahwa noise yang kami reduksi ialah noise multi frekuensi, bukan noise single frekuensi]
Implementasi System
[bagian ini hanya diambil sebagaian saja, on request
 ]
]Hardware untuk pengenalan suara meliputi unit komputer (dengan soundcard), microphone, dan sirkuit pengontrol motor berbasis mikrokontroller AT89S2051 yang terhubung ke PC melalui serial link.
Data base sample suara menggunakan suara dari 4 orang.
Berikut tampilan window di PC ketika berhasil mengenali suara.
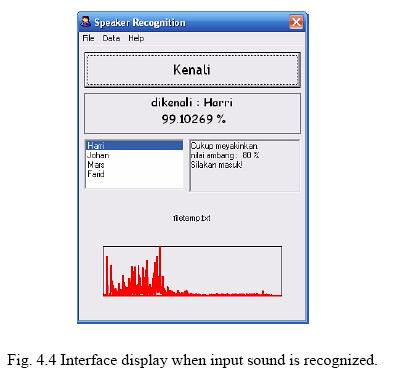
Jaringan syaraf tiruan kami menggunakan 12 spektrum suara dari 4 orang sebagai referensi belajar. Training untuk 100 epoch dengan laju belajar 0.75, faktor momentum 0.75 dan kemiringan fungsi logistik 0.01 menghasilkan error global 0.065.
Ringkasan
Spektrum noise dapat dieliminasi menggunakan metode self miltiplication dengan beberapa keterbatasan. Metode ini membagi dua sinyal input (dalam domain waktu), mentransformasi tiap sinyal ke domain frekuensi, dan mengalikan kedua sinyal konponen-per-komponen.
Dalam online test (real case test), jaringan syaraf tiruan kami hanya berhasil mengenali satu dari empat orang secara baik (kepercayaan > 80%) berdasarkan spektrum suara, sisanya hanya dikenali dengan persentasi kepercayaan < 80%.
Referensi
[1]
Discovery Channel. 2057: The City. (a documentary movie)
[2]
Forming the Vowel Sounds. Available at: http://hyperphysics.phy-astr.gsu.edu/hbase/music/vowel.html
[3]
Anil K. Jain (Michigan State Univ.), Jianchang Mao and K. M. Mohiuddin (IBM Almaden Research Center). Artificial Neural Networks: A Tutorial. Pp. 39, March 1996.
[4]
Backpropagation. Available at: http://en.wikipedia.org/wiki/Backpropagation. Last modified: 24 June 2007.
[5]
Ben Kröse (Fac. of Math. And Comp. Sci., Univ. of Amsterdam), Patrick van der Smagt (Inst. of Robotics and Sys. Dynamics, German Aerospace Research Establish). An Introduction to Neural Networks, 8th Ed. Pp. 37, November 1996.
sumber : http://www.forumsains.com/index.php?page=pengenalan-suara-berbasis-neural-network-dengan-algoritma-momentum-back-propagation